
Github Actions - Parallelised builds with caching
TL;DR - Define several jobs in a workflow, and use the cache action
Previous post
In this previous post, we learned how to setup a Github Actions workflow and run it from a working branch while it was still under development. Now, let's look at how we can use parallel jobs with caching in order to separate and speed up our workflows. This enables specifying which parts of the workflow are critical and dependant, and which parts are optional.
Parallel Builds
Let's jump right in to the build.yml file from before, and make some changes. We'll add the trigger to include push events from all branches, and under the jobs object, we'll add some properties. Congrats, your workflow is now parallelised.
Each job runner needs to run on something, e.g. a predefined OS or container. A list of available runners can be found here. This is set by the runs-on keyword. If you want to mix parallel and sequential jobs, you can use the needs keyword. It specifies which jobs need to be completed before that job runs. In the example above, we see that the Setup job precedes the code quality related jobs, and the build needs all those to complete before triggering.
The Setup Job
Ideally, we'll perform tasks here that can benefit upcoming jobs somehow. In our case, we want to install and cache our dependencies. This allows other jobs to re-use what's in the cache to increase the overall workflow speed. Let's have a look:
Each step in a job is an entry in the steps list. The name property will be shown in the Github Actions GUI. The GUI will show that the action uses identifier if name is omitted. Since we're working on the repository with yarn commands, the runner must have access to the code, this is what the checkout step is for. The setup-node action with node version 14 has yarn enabled by default.
The next two steps are for the cache, and since we use yarn here we first set the yarn cache directory so that the cache@v2 action can use it. The cache action has recently enabled multiple directories, and for this setup we'll add:
- the yarn cache directory - this is used so that yarn doesn't download packages from the web on each install, making installs a lot faster.
node_modules- contains all dependencies and their binaries. This will take up quite a lot of space so make sure you're within the Github Actions cache limit.- the Cypress cache - We're using Cypress for our E2E tests. Without this cached, this error was thrown:
The cypress npm package is installed, but the Cypress binary is missing. We expected the binary to be installed here: /home/runner/.cache/Cypress/7.3.0/Cypress/Cypress Reasons it may be missing:
- You're caching 'node_modules' but are not caching this path: /home/runner/.cache/Cypress
- You ran 'npm install' at an earlier build step but did not persist: /home/runner/.cache/Cypress
Properly caching the binary will fix this error and avoid downloading and unzipping Cypress.
The other jobs
Now the Setup job has run, installed and cached the dependencies, so any upcoming installs will be quick work. In order for the other jobs to use the yarn dependencies cache, simply copy / paste the cache steps from before.
In the UnitTest job below, note a few things:
- we specify that it's dependant on
Setupjob, this ensures that Setup must complete successfully before UnitTest starts. - we need to checkout the code, retrieve the cahce and perform an install again. We tell yarn to install from the local cache by passing the
--prefer-offlineargument. - If we were to omit the cache and install, the
yarn testwould likely trigger something likejest, which wouldn't exist in this Github Actions runner, since each runner is a separate fresh instance.
Run in parallell
Now, how do we get the jobs to run in parallel? Simply by declaring several jobs (as opposed to one almighty job), and specifying which job needs which in order to run, we get the runners to run in parallell. Note how UnitTest, E2ETest, and StaticAnalysis all declare a dependency on Setup, this ensures they will run independent from each other.
It is also possible for a job to not be referenced by other jobs, and not specify any needs. This type of job will also run in parallel but won't affect or depend on the others. It's clearly a separate island in the workflow depiction below:
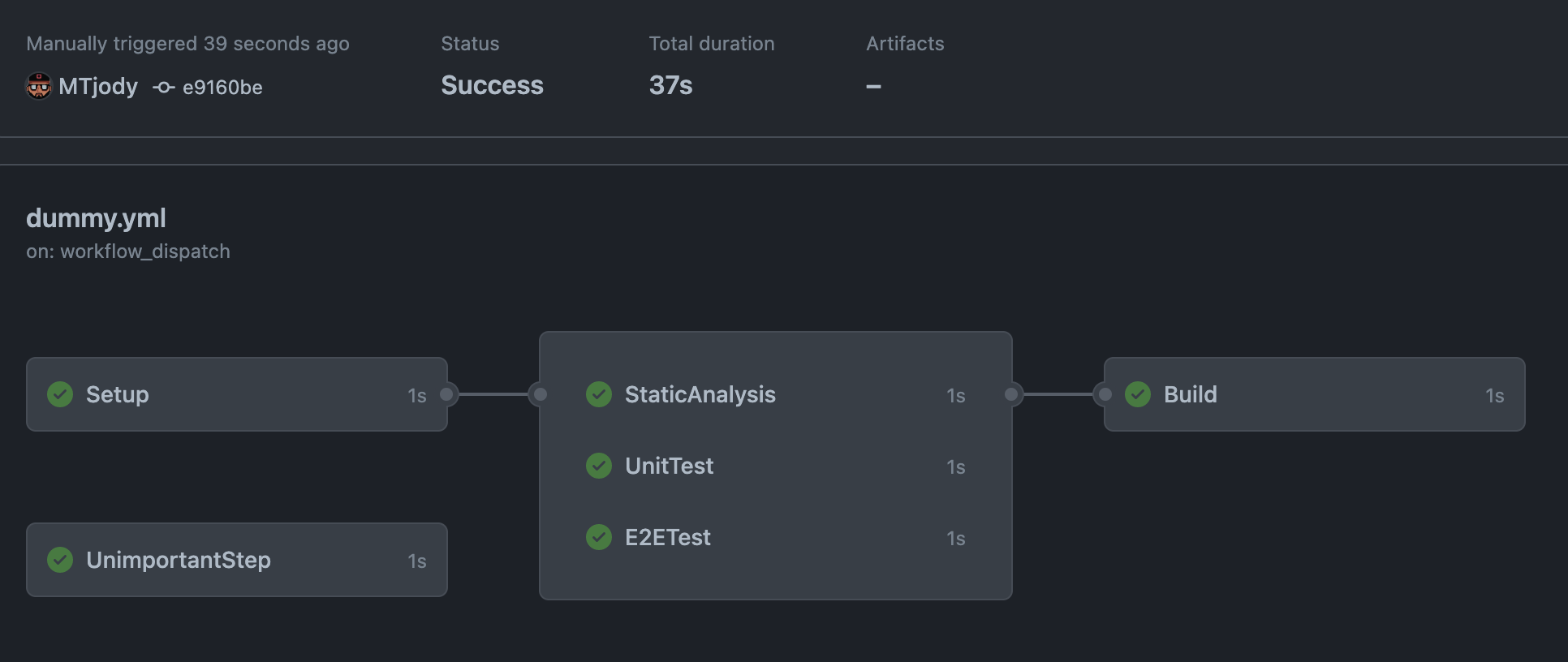
Another benefit from this compared to a single huge job is that when one step fails, the whole workflow isn't cancelled. This means that e.g. if the static code analysis fails, we'll still know if the unit tests and E2E tests passed, as opposed to finding that out once the static analysis passes.
In my latest project, using the cache resulted in a drastic performance boost for the installation step. Without the cache, the installation took ~2min 30s. When adding the yarn.lock cache it went down to 1min. When caching both the yarn.lock and node_modules it only took 2s. That's 75x faster! The trade-off comes in the cache-retrieval though, which now takes ~30s, but that's still a massive improvement overall (5x). Also note that if your dependencies are updated, the yarn.lock will have been updated, leading to a new cache which results in a slower Setup job.
What the future holds
In an upcoming post, we'll look into how to setup "job guards" which require manual approval in order to run, these can typically be used in a deployment scenario where you'd want some reviewer(s) to make sure everything is in order.